RSS配信記事




multipathでデバイス名を変更する方法について
[対象となる製品のバージョン]
![]() Asianux Server 3 for x86(32bit)
Asianux Server 3 for x86(32bit)
![]() Asianux Server 3 for x86-64(64bit)
Asianux Server 3 for x86-64(64bit)
[概 要]
Asianux Server 3でmultipathを使用する事によって、デバイスファイル名を変更する方法を記述します。
[説 明]
# /sbin/scsi_id -g -u -s /block/sd[a-q]
defaults {
user_friendly_names yes
}
2-2. "1."のコマンドで確認したwwidを使いデバイス名の紐付けを行います。
multipaths {
multipath {
wwid 6d00112744ac7f00023f6c15c0ff8313c
alias mpath0
}
}
3-1. device mapをクリアします。
# /sbin/multipath -F
3-2. 以下のコマンドで設定を反映した新しいdevice mapを作成します。
# /sbin/multipath -v2 -l
# chkconfig multipathd on
# service multipathd start
# multipath -ll
# multipath -ll
mpath0 (xxxxxxxxxxxx) dm-0 xxxxx,xxxxx
[size=204G][features=0][hwhandler=0][rw]
\_ round-robin 0 [prio=0][active]
\_ 1:0:0:0 sda 8:0 [active][ready]
\_ 2:0:0:0 sdb 8:16 [active][ready]
例)
devices {
device {
vendor "YYYYY"
product "xxxx RAID"
path_grouping_policy multibus
getuid_callout "/sbin/scsi_id -g -u -s /block/%n"
prio_callout "/bin/true"
features "0"
path_checker readsector0
failback immediate
}
}
-
immediate障害発生時、パス回復後すぐにパスを有効にします。<数字>障害発生時、パス回復後<数字>秒後にパスを有効にします。manual障害発生時、パス回復後手動で復旧させる必要があります。
udevを使用してデバイスファイル名を固定する方法
http://www.miraclelinux.com/support/?q=node/269
SSHで接続したリモートホストのGUIアプリケーションを使用する方法
![]() Asianux Server 3 for x86(32bit)
Asianux Server 3 for x86(32bit)
![]() Asianux Server 3 for x86-64(64bit)
Asianux Server 3 for x86-64(64bit)
![]() MIRACLE LINUX V4.0 - Asianux Inside
MIRACLE LINUX V4.0 - Asianux Inside
![]() MIRACLE LINUX V4.0 - Asianux Inside for x86-64
MIRACLE LINUX V4.0 - Asianux Inside for x86-64
OpenSSH の X11 forwarding 機能を使用すると、sshで接続した先のホスト(SSHサーバ)のGUIアプリケーションを接続元のホスト(SSHクライアント)で使用することができます。
1. 接続先のホスト(SSHサーバ)において、sshdの設定を行います。
設定ファイル: /etc/ssh/sshd_config
X11Forwarding yes
2.設定を有効にするため、sshdを再起動します。
# service sshd restart
1. 接続を行うホスト(SSHクライアント)から接続を行います。
# ssh -X -l ログイン名 ホスト名
-X : X11 forwarding機能を有効にする
-l : ログイン名
# firefox
# firefox &
# gvim &
2010年 12月 17日 新規作成
IPMI Watchdogが機能しない
![]() Asianux Server 3 for x86(32bit)
Asianux Server 3 for x86(32bit)
![]() Asianux Server 3 for x86-64(64bit)
Asianux Server 3 for x86-64(64bit)
※kernel-2.6.18-194.1.AXS3(Asianux Server 3 SP3収録)以降のバージョンをご使用の場合
IPMI watchdogが機能しません。ipmi_watchdog ドライバをロードすると下記のメッセージが出力されます。
IPMI Watchdog: Unable to register misc device
Asianux Server 3 SP3(kernel-2.6.18-194.1.AXS3)から追加されたiTCO_wdtドライバが、ipmi_watchdogドライバをロードするよりも先にロードされている場合この現象が発生します。
iTCO_wdtドライバは、インテルICHに内蔵されているwatchdogデバイス(intel TCO timer based watchdog device)のためのドライバです。
iTCO_wdtドライバとipmi_watchdogドライバは同時に使用することができません。
1.下記のコマンドで、iTCO_wdtドライバがロードされていることを確認します。
# lsmod grep iTCO_wdt
iTCO_wdt 17956 0
2.IPMI Watchdogを使用するには、iTCO_wdtドライバをロードさせない設定を行う下記の方法が考えられます。
1) 下記のファイルにinstallの行を追加します。
ファイル: /etc/modprobe.conf
install iTCO_wdt /bin/true
2) 設定を反映するためOSを再起動します。
方法2: iTCO_wdtドライバをロードしないようにする。
1) 下記のファイルにblacklistの行を追加します。
ファイル: /etc/modprobe.d/blacklist
blacklist iTCO_wdt
2) 設定を反映するためOSを再起動します。
IPMI watchdogの設定方法
2010年 12月 17日 新規作成
snmpdから出力されるメッセージについて
![]() Asianux Server 3 for x86(32bit)
Asianux Server 3 for x86(32bit)
![]() Asianux Server 3 for x86-64(64bit)
Asianux Server 3 for x86-64(64bit)
snmpd[8904]: netsnmp_assert !"registration !=duplicate" failed agent_registry.c:536 netsnmp_subtree_load()
2010年 11月 29日 新規作成
proftpdを使用しているFTPサーバに対してFTPファイル転送中にABORを発行すると6分間停止してしまう
![]() MIRACLE LINUX V4.0 - Asianux Inside
MIRACLE LINUX V4.0 - Asianux Inside
![]() MIRACLE LINUX V4.0 - Asianux Inside for x86-64
MIRACLE LINUX V4.0 - Asianux Inside for x86-64
クライアントからABORが発行されると、サーバとクライアントの両方でお互いのセッションがク
ローズを待ってしまいデッドロック状態に陥ってしまいます。6分経過後、サーバ側でタイムアウ
proftpd.confの終端に "TimeoutLinger 5"の設定を追記してください。
...中略
</Anonymous>
TimeoutLinger 5
設定後、proftpdは再起動またはrereadによる設定ファイルの再読み込みが必要となります。
本ドキュメントは、限られた評価環境における検証結果をもとに作成しており、 全ての環境での動作を保証するものではありません。
本ドキュメントの内容に基づき、導入、設定、運用を行なったことにより損害が 生じた場合でも、弊社はその損害についての責任を負いません。あくまでお客様のご判断にてご使用ください。
2010年 11月19日 新規作成
異なるベンダーのハードディスクで同じブロック数に設定してパーティションを区切る方法
![]() Asianux Server 3 for x86(32bit)
Asianux Server 3 for x86(32bit)
![]() Asianux Server 3 for x86-64(64bit)
Asianux Server 3 for x86-64(64bit)
![]() MIRACLE LINUX V4.0 - Asianux Inside
MIRACLE LINUX V4.0 - Asianux Inside
![]() MIRACLE LINUX V4.0 - Asianux Inside for x86-64
MIRACLE LINUX V4.0 - Asianux Inside for x86-64
Software RAID1(ミラー)で構成している環境で、1台ハードディスクを交換しようとしたが、異なるベンダーのハードディスクのため、パーティションを区切る際に同じブロック数にならず、RAID構成を復旧させることができませんでした。元のディスクと同一のブロック数にパーティションを切ることができれば、復旧できそうなのですが、パーティションのブロック数を指定する方法はありませんでしょうか?
●元ハードディスク
Device Boot Start End Blocks Id System
/dev/sdak1 1 131 1052257 83 Linux
/dev/sdak2 132 262 1052257+ 83 Linux
●新ハードディスク
Device Boot Start End Blocks Id System
/dev/sdy1 1 131 1052226 83 Linux
異なるベンダーのハードディスクでは、1シリンダ内に配置できるブロック数が異なる場合がある
fdiskコマンドを使用する場合は、セクタ単位に指定することで、ブロック数を一致させることが
1. fdisk /dev/sdak
2. セクタ単位に変更(u)
コマンド (m でヘルプ): u
セクタ数 の表示/項目ユニットを変更します
3. パーティションを作成
コマンド (m でヘルプ): n
コマンドアクション
e 拡張
p 基本領域 (1-4)
p
領域番号 (1-4): 1
最初 セクタ (1-1953520064, default 1):
Using default value 1
終点 セクタ または +サイズ または +サイズM または
+サイズK (1-1953520064, default 1953520064): +2104514
※1セクタ512バイトの場合2104514セクタを使用すると1052257 blockになります
環境により適宜数値を変更する必要があります。
4. 確認(セクタで表示されます)
コマンド (m でヘルプ): p
255 heads, 63 sectors/track, 121601 cylinders, total 0 sectors
Units = セクタ数 of 1 * 512 = 512 bytes
デバイス Boot Start End Blocks Id System
sdak1 1 2104515 1052257+ 83 Linux
Partition 1 does not end on cylinder boundary.
5. 確認(シリンダ数(デフォルトの表示)で表示)
コマンド (m でヘルプ): u
シリンダ数 の表示/項目ユニットを変更します
コマンド (m でヘルプ): p
デバイス Boot Start End Blocks Id System
sdak1 1 132 1052257+ 83 Linux
Partition 1 does not end on cylinder boundary.
fdisk時に表示される"Partition 1 does not end on cylinder boundary."については、シリンダ終端 に合った設定では無いという意味になります。
1シリンダの途中でパーティションを切ることにより、シークが増え、パフォーマンスにペナルティが ある場合もありますので、ご注意ください。
本ドキュメントは、限られた評価環境における検証結果をもとに作成しており、 全ての環境での動作を保証するものではありません。
本ドキュメントの内容に基づき、導入、設定、運用を行なったことにより損害が 生じた場合でも、弊社はその損害についての責任を負いません。あくまでお客様のご判断にてご使用ください。
2010年 11月19日 新規作成
ethtoolコマンドの-dオプションについて
![]() MIRACLE LINUX V4.0 - Asianux Inside
MIRACLE LINUX V4.0 - Asianux Inside![]() MIRACLE LINUX V4.0 - Asianux Inside for x86-64
MIRACLE LINUX V4.0 - Asianux Inside for x86-64
# /sbin/ethtool -d eth0
Cannot dump registers: Success
[原因 ・対処]
Miracle Linux 4 SP2までに含まれるethtool バージョン1.8-4は-dオプションがサポートされておりません。下記URLよりethtool-6-1以上のバージョンをダウンロードし、アップデートしてください。
# ethtool -d eth0
MAC Registers
-------------
0x00000: CTRL (Device control register) 0x180C0241
Endian mode (buffers): little
Link reset: normal
Set link up: 1
Invert Loss-Of-Signal: no
Receive flow control: enabled
・・・・・
2010年 11月 19日 新規作成
authdパッケージアップデートで出力されるメッセージについて
パッケージのアップデートをすると最後に”設定を再読み込み: [失敗]”と出力される
[対象となる製品のバージョン]
![]() Asianux Server 3 for x86(32bit)
Asianux Server 3 for x86(32bit)
![]() Asianux Server 3 for x86-64(64bit)
Asianux Server 3 for x86-64(64bit)
[原因 ・対処]
Asianux TSN Updater(axtu)やAsianux Server 3 ==MIRACLE LINUX V5 のDVDメディアを使用して、SPのアップデートを実施した際に最後の以下のようなメッセージが出力されることがあります。
・・・・・
571:xorg-x11-drivers ##################################### [100%]
572:xorg-x11-drv-i810-devel##################################### [100%]
設定を再読み込み: [失敗]
#
このメッセージはauthdパッケージのアップデートにより出力されます。authdはアップデートされるとxinetdを再起動し、authd自身が更新されたもので動作するようになっています。このときxinetdが停止しているとauthdも再起動されないため本メッセージが出力されます。本メッセージが出力されても動作に影響はございません。
本ドキュメントは、各ソフトウェア開発元の情報およびマニュアル等を元にした参考情報です。
本ドキュメントの内容は、予告なしに変更される場合があります。
本ドキュメントは、限られた評価環境における検証結果をもとに作成しており、全ての環境での動作を保証するものではありません。
本ドキュメントの内容に基づき、導入、設定、運用を行なったことにより損害が生じた場合でも、弊社はその損害についての責任を負いません。あくまでお客様のご判断にてご使用ください。
2010年 11月15日 新規作成
CLUSTERPROでVMware ESXのHW障害をトリガーに仮想マシン上の業務をフェイルオーバさせる方法
[概要]
本書では、VMwareサービスコンソール上にCLUSTERPRO X Single Server Safe、ゲストOS上にCLUSTERPRO Xを構築し、それぞれ連携させることで、堅牢な仮想化環境ソリューションを構築します。
[使用した製品のバージョン]
MIRACLE CLUSTERPRO X2.1
- Asianux Server 3 ==MIRACLE LINUX V5 SP3
- clusterpro-2.1.5-1
VMware ESX4.0
- clusterprosss-2.1.5-1
[ 検証内容]
VMware ESX4.0のサービスコンソールにはCLUSTERPRO Single Server Safe(以下SSS) または
CLUSTERPRO X2.1 をインストールすることができます。
CLUSTERPROのクラスタ間処理要求機能を使い、VMware ESXのサービスコンソール-GuestOS間で連携を行い、物理マシン のHW障害からGuestOS上の業務までの障害に対応できるよう設定します。
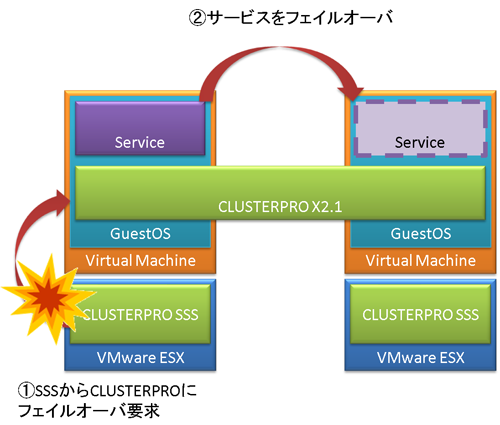
本検証ではサービスコンソール上にCLUSTERPRO SSS、GuestOSにCLUSTERPROをインストールします。
物理サーバのHW障害時はサービスコンソールにインストールされたCLUSTERPRO SSSがGuestOS上のCLUSTERPROにフェイルオーバのリクエストを送ります。リクエストを受けたGuestOS上で業務が待機系にフェイルオーバします。
[環境構築]
なお、本手順ではすでに物理サーバにVMware ESXがインストールされ、仮想マシンが作成されているものとします。
この際、クラスタ間処理要求機能を使って、サービスコンソール上のCLUSTERPRO SSSから仮想マシン上のCLUSTERPROへ処理要求を出せるよう、設定を行います。
# mkdir /opt/nec/clusterpro/work/clptrnreq
以下は、VMware ESXサービスコンソール上のCLUSTERPRO SSSからフェイルオーバリクエストを受信したメッセージを出力させるスクリプトです。
#!/bin/bash
/usr/sbin/clplogcmd -m "Receive Failover Request from ESX" -l warn
ここでは以下のように設定しました。
|
クラスタシステム設定
|
||
|
クラスタ構成
|
クラスタ名
|
VMcluister
|
|
サーバ数
|
2
|
|
|
1台目のサーバ
|
サーバ名
|
CLP-1
|
|
OS
|
Asianux Server 3
|
|
|
パブリックのIPアドレス
|
10.2.102.51
|
|
|
インタコネクトのIPアドレス
|
192.168.10.1
|
|
|
10.2.102.51
|
||
|
2台目のサーバ
|
サーバ名
|
CLP-2
|
|
OS
|
Asianux Server 3
|
|
|
パブリックのIPアドレス
|
10.2.102.52
|
|
|
インタコネクトのIPアドレス
|
192.168.10.2
|
|
|
10.2.102.52
|
||
-
グループリソース設定グループ名failoverfloating ip resourceグループリソース名fipIPアドレス10.2.102.50活性リトライ5回フェイルオーバー1回活性最終動作何もしない(次のリソースを活性しない)非活性リトライ0回非活性最終動作クラスタデーモン停止とOSシャットダウンmirror disk resourceグループリソース名mdマウントポイント/dataデータパーティション/dev/sda4クラスタパーティション/dev/sda3ディスクデバイス名/dev/sdaファイルシステムext3活性リトライ0回フェイルオーバー1回活性最終動作何もしない(次のリソースを活性しない)非活性リトライ0回非活性最終動作クラスタデーモン停止とOSシャットダウンexecute resourceグループリソース名exec活性リトライ0回フェイルオーバー1回活性最終動作何もしない(次のリソースを活性しない)非活性リトライ0回非活性最終動作クラスタデーモン停止とOSシャットダウン
-
モニタリソース設定user mode monitor
(自動登録)モニタソース名userw監視方法softdogNIC Link Up/Down
monitor
(全物理NICごと)モニタリソース名miiw-eth0監視デバイスeth0回復対象vmcluster活性リトライ0回フェイルオーバー0回活性最終動作何もしないNIC Link Up/Down
monitor
(全物理NICごと)モニタリソース名miiw-eth1監視デバイスeth1回復対象vmcluster活性リトライ0回フェイルオーバー0回活性最終動作何もしないmirror disk monitor
モニタリソース名mdw1ミラーディスクリソースmd回復対象VMcluster活性リトライ0回フェイルオーバー0回活性最終動作何もしないmirror disk
connect monitor
モニタリソース名mdnw1ミラーディスクリソースmd回復対象VMcluster活性リトライ0回フェイルオーバー0回活性最終動作何もしない
3.VMware ESXサービスコンソール上にCLUSTERPRO SSSの構築
VMware ESXのサービスコンソールにCLUSTERPRO SSSをインストールします。
なお、GuestOSの障害対策はGuestOS上のCLUSTERPROで行うため、仮想マシン自体はCLUSTERPRO SSSの管理外とします。
VMware ESX4.0のサービスコンソールはRHEL5-x86_64に相当するため、Linux版のCLUSTERPRO SSSをインストールすることができます。
# rpm -ivh clusterprosss-2.1.5-1.x86_64.rpm
VMware ESXではデフォルトではFireWallが有効になっているため、CLSUTERPRO SSSを利用する上で必要なポートを開放します。
# esxcfg-firewall -o 29003,tcp,in,clpwebmgr
# esxcfg-firewall -o 29002,tcp,out,clptrnsrv
VMware ESXではuserw(user空間監視)でipmi、softdogを指定しているとエラーとなります。
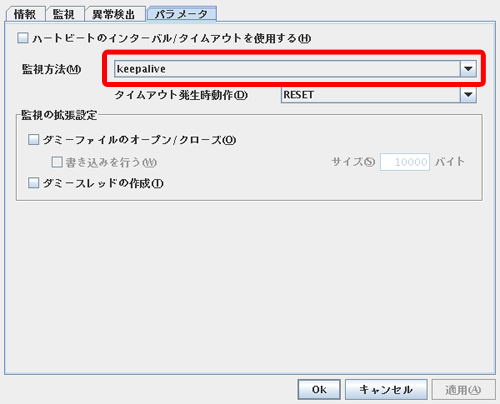
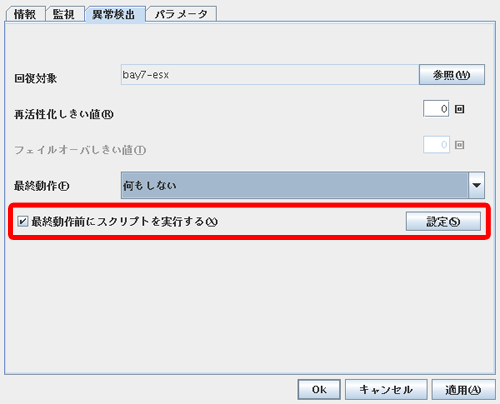
VMware ESXハイパーバイザ上のCLUSTERPRO SSSのモニタリソースが反応したら、GuestOS上のCLUSTERPROにフェイルオーバリクエストを発行し、GuestOS上で動作している業務を待機系にフェイルオーバさせます。
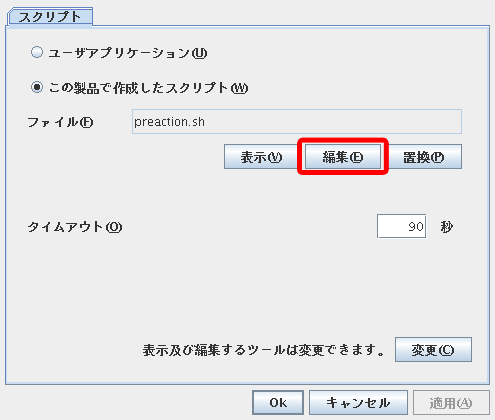
#! /bin/sh
#***********************************************
#* preaction.sh *
#***********************************************
*****************************************
ulimit -s unlimited
# ホストマシンが起動する仮想マシンのリソース名を記述
CLPRSC="exec"
# カンマ区切りで各ホストマシンの IP を記述
CLPIP="10.2.102.51,10.2.102.52"
/usr/sbin/clplogcmd -m "Send Failover Request to CLP-1" -l warn
/usr/sbin/clptrnreq -t EXEC_SCRIPT -h $CLPIP -s failover_message.sh
/opt/nec/clusterpro/bin/clptrnreq -t GRP_FAILOVER -r $CLPRSC -h $CLPIP
exit 0
以上で設定は完了です。
|
クラスタシステム設定
|
||
|
クラスタ構成
|
クラスタ名
|
bay7-esx
|
|
サーバ数
|
1
|
|
|
1台目のサーバ
|
サーバ名
|
bay7-esx
|
|
OS
|
VMware ESX 4
|
|
|
パブリックのIPアドレス
|
10.2.102.17
|
|
-
モニタリソース設定user mode monitor
(自動登録)モニタソース名userw監視方法keepaliveNIC Link Up/Down
monitor
(全物理NICごと)モニタリソース名miiw-vmnic0監視デバイスvmnic0回復対象bay7-esx活性リトライ0回活性最終動作何もしないNIC Link Up/Down
monitor
(理NICごと全物)モニタリソース名miiw-vmnic1監視デバイスvmnic1回復対象bay7-esx活性リトライ0回最終活性動作何もしないcustom monitor
(必要に応じて)モニタリソース名genw-CLP1監視方法□ユーザアプリケーション■スクリプトファイルGenw.sh監視スクリプト前述の仮想マシン監視スクリプト監視タイプ■同期□非同期ログ出力先正常な戻り値0回復対象bay7-esx活性リトライ0回活性最終動作何もしないcustom monitor
(必要に応じて)モニタリソース名genw-CLP2監視方法□ファイルGenw.sh監視スクリプト前述の仮想マシン監視スクリプト監視タイプ■ログ出力先正常な戻り値0回復対象bay7-esx活性リトライ0回活性最終動作何もしない
本検証では、VMware ESXがインストールされた物理マシンのNIC(vmnic1) を抜き、CLUSTERPRO SSSのNICLink Up/Down monitorがリンクダウンを検知したら、GuestOS上で動作しているApacheをフェイルオーバさせます。
VMware ESXサービス近ソース上のCLUSTERPRO SSS
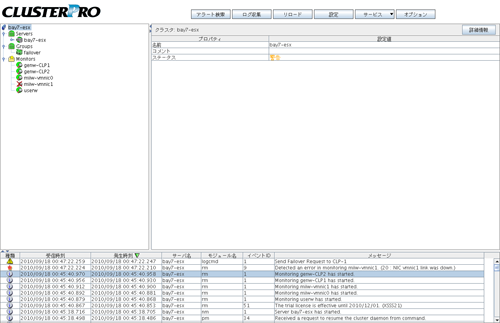
2010/09/24 21:18:18 bay7-esx rm Detected an error in monitoring miiw-vmnic1. (20 : NIC vmnic1 link was down.) ←vmnic1リンクダウン検知
2010/09/24 21:18:18 bay7-esx logcmd Send Failover Request to CLP-1 ←最終動作前のスクリプト実行
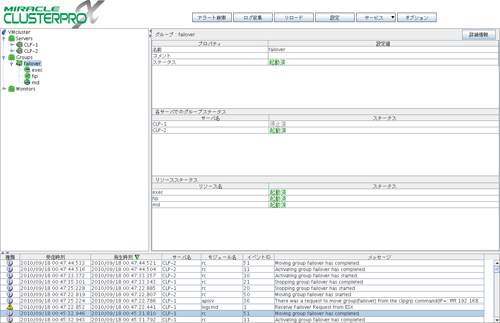
GuestOS上のMIRACLE CLUSTERPRO
2010/09/24 21:18:18 CLP-1 logcmd Receive Failover Request from ESX ←メッセージ出力
2010/09/24 21:18:18 CLP-2 logcmd Receive Failover Request from ESX ←メッセージ出力
2010/09/24 21:18:19 CLP-1 apisv There was a request to move group(failover) from the clpgrp command(IP=::ffff:192.168.10.101). ←フェイルオーバ開始
2010/09/24 21:18:19 CLP-1 rc Stopping group failover has started.
2010/09/24 21:18:19 CLP-2 rc Moving group failover has started.
2010/09/24 21:18:31 CLP-1 rc Stopping group failover has completed.
2010/09/24 21:18:31 CLP-2 rc Activating group failover has started.
2010/09/24 21:18:42 CLP-2 rc Activating group failover has completed.
2010/09/24 21:18:42 CLP-2 rc Moving group failover has completed. ←フェイルオーバ完了
本ドキュメントは、限られた評価環境における検証結果をもとに作成しており、 全ての環境での動作を保証するものではありません。

NetVault Backupの障害発生時の初動調査および情報採取のための事前準備
[概要]
本ドキュメントでは、NetVault Backupで障害発生時に、お問合せの前に事前に確認、準備すべき内容について説明します。
[対象となる製品のバージョン]
NetVault Backup 8.1以降
[注意事項]
[初動調査]
[情報採取のための事前準備]
ミラクル・リナックス カスタマーサポートセンターでは、[初動調査]と併せて、現象に応じた情報採取をお願いしています。採取依頼のあった情報を採取できるように、事前に準備をしていただくことをお勧めします。
MIRACLE LINUX、Asianuxをお使いの場合は、/usr/sbin/mcinfo を利用します。
なお、mcinfoの取得情報の中には、rootユーザーでしか取得できないものもあるため、/usr/sbin/mcinfo コマンドはrootユーザーで実行します。
・MIRACLE LINUX v4.0 SP2 より前のバージョンをご使用の場合
# mcinfo | gzip > mcinfo.log.gz
・MIRACLE LINUX v4.0 SP3、Asinaux Server 3 == MIRACLE LINUX V.5 以降をご使用の場合
# mcinfo
■ NetVault Backupのバイナリログ取得
NetVault BackupではNetVault GUIのLogsからログの参照が可能です。
NetVault backupのログ収集はNetVault GUIを使いGUIで行う方法と、コマンドで行う方法があります。これらは、どちらの方法でも同じ情報が取得されます。
・NetVault GUIからログを取得する方法
以下のコマンドを実行してnetVault GUIを起動します。
# nvgui
netVault GUIが起動したら、[ログ]を選択します。
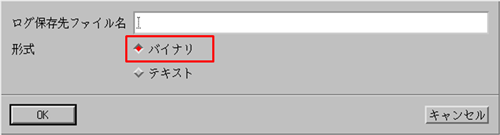
以下の例では "nvbinlog20040607_02.nlg"というファイル名で2004年1月1日 00:00.00〜2004年12月31日 23:59.59までのログをとるよう指定しています。
# cd /usr/netvault/util/
# ./nvlogdump -filename nvbinlog20040607_02 -starttime 20040101000000 -endtime 20041231235959
上記コマンドを実行すると、NetVault GUIを使ってのログ取得と同様、/usr/netvault/logs/dumps/binary以下に指定したファイル名でログが保存されます。
CLUSTERPROの障害発生時の初動調査および情報採取のための事前準備
[概要]
[対象となる製品のバージョン]
CLUSTERPRO X3
CLUSTERPRO X2.1
CLUSTERPRO X2.0
CLUSTERPRO X1.0
CLUSTERPRO for Linux Ver3.x SE/LE
[注意事項]
[初動調査]
[情報採取のための事前準備]
ミラクル・リナックス カスタマーサポートセンターでは、[初動調査]と併せて、現象に応じた情報採取をお願いしています。採取依頼のあった情報を採取できるように、事前に準備をしていただくことをお勧めします。
MIRACLE LINUX、Asianuxをお使いの場合は、/usr/sbin/mcinfo を利用します。
なお、mcinfoの取得情報の中には、rootユーザーでしか取得できないものもあるため、/usr/sbin/mcinfo コマンドはrootユーザーで実行します。
・MIRACLE LINUX v4.0 SP2 より前のバージョンをご使用の場合
# mcinfo | gzip > mcinfo.log.gz
・MIRACLE LINUX v4.0 SP3、Asinaux Server 3 == MIRACLE LINUX V.5 以降をご使用の場合
# mcinfo
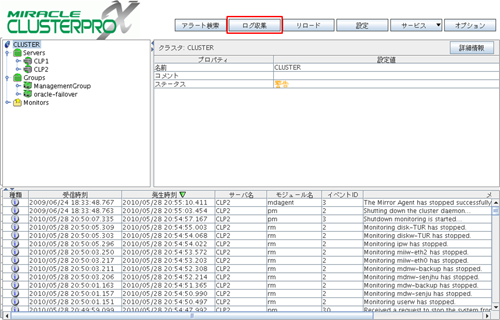
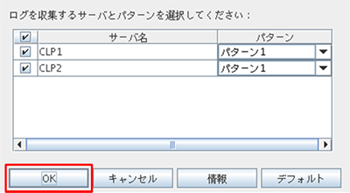
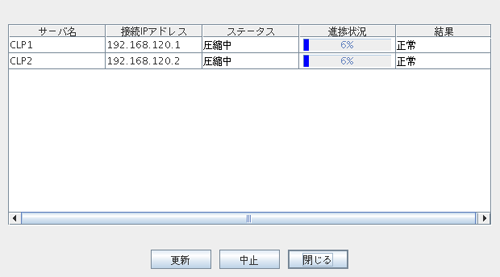
# clplogcc -o <ログ出力先ディレクトリパス>
ネットワーク帯域制御CBQを使用するときの注意事項
[対象となる製品のバージョン]
![]() Asianux Server 3 for x86(32bit)
Asianux Server 3 for x86(32bit)
![]() Asianux Server 3 for x86-64(64bit)
Asianux Server 3 for x86-64(64bit)
[質 問]
CBQ(Class Baased Queueing)を使用しネットワークの帯域制御をすると極端にスループットが低下する
一部のネットワークカードで、CBQによる送信パケットの帯域制御を行うと設定値よりも大幅にスループットが制限されることがあります。
本問題の対処方法としてTSOを無効にすることで改善される場合があります。
例) eth0として認識しているネットワークカードのTSOを無効にする場合
# ethtool -K eth0 tso off
# ethtool -k eth0
Offload parameters for eth0:
Cannot get device udp large send offload settings: Operation not supported
rx-checksumming: on
tx-checksumming: on
scatter-gather: on
tcp segmentation offload: off ← offであることを確認してください
udp fragmentation offload: off
generic segmentation offload: off
[更新履歴]
2010年 5月 26日 新規作成
『/var/log/rflogview』ディレクトリが肥大化する
[対象となる製品のバージョン]
![]() Asianux Server 3 ==MIRACLE LINUX V5 for x86(32bit)
Asianux Server 3 ==MIRACLE LINUX V5 for x86(32bit)
![]() Asianux Server 3 ==MIRACLE LINUX V5 for x86-64(64bit)
Asianux Server 3 ==MIRACLE LINUX V5 for x86-64(64bit)
![]() MIRACLE LINUX V4.0 - Asianux Inside for x86(32bit)
MIRACLE LINUX V4.0 - Asianux Inside for x86(32bit)
![]() MIRACLE LINUX V4.0 - Asianux Inside for x86-64(64bit)
MIRACLE LINUX V4.0 - Asianux Inside for x86-64(64bit)
[質 問]
ディレクトリ 『/var/log/rflogview』 が肥大化する
『/var/log/rflogview』は後述のlime-logview(rflogview)※が使用するディレクトリです。サーバーのご使用の方法によってはこのディレクトリの容量が非常に大きくなることがありご運用の際は注意が必要です。
※プログラムの名称はOSにより下記のように異なります。
|
OS |
プログラム名
|
|
Asianux Server 3 ==MIRACLE LINUX V5 |
lime-logview |
|
MIRACLE LINUX V4.0 |
rflogview |
[lime-logview(rflogview)とは]
ログファイルを整形し、GUIで表示するツールです。syslogメッセージをシステム、ブート、セキュリティ、メールに分類して表示します。
[対処方法]
lime-logview(rflogview)を使用しない場合は下記の手順にて、このディレクトリへのログ出力を止め、ログファイルとパッケージを削除することが可能です。
1. 下記 syslogの設定ファイルから rflogview の設定項目を削除します。
ファイル: /etc/syslog.conf
下記の行を削除します。
###rflogview_begin#### this is begin flag line , do not midify it !
#do not insert your own rules between the begin flag line to the end flag line.
#system
kern.err;cron.err;daemon.err;lpr.err;news.err;uucp.err;syslog.err -/var/log/rflogview/system_errors
kern.=info;kern.=notice;cron.=info;cron.=notice;daemon.=info;daemon.=notice;lpr.=info;lpr.=notice;uucp.=info;uucp.=notice;sysl
og.=info;syslog.=notice;news.=info;news.=notice -/var/log/rflogview/system_info
kern.=warn;cron.=warn;daemon.=warn;lpr.=warn;news.=warn;uucp.=warn;syslog.=warn -/var/log/rflogview/system_warnings
#user
user.=info;user.=notice -/var/log/rflogview/user_info
user.=warn -/var/log/rflogview/user_warnings
user.err -/var/log/rflogview/user_errors
mail.=info;mail.=notice -/var/log/rflogview/mail_info
mail.=warn -/var/log/rflogview/mail_warnings
mail.err -/var/log/rflogview/mail_errors
#secure
auth.=info;auth.=notice;authpriv.=info;authpriv.=notice -/var/log/rflogview/secure_info
auth.=warn;authpriv.=warn -/var/log/rflogview/secure_warnings
auth.err;authpriv.err -/var/log/rflogview/secure_errors
#boot
local7.=info;local7.=notice -/var/log/rflogview/boot_info
local7.=warn -/var/log/rflogview/boot_warnings
local7.err -/var/log/rflogview/boot_errors
###rflogview_end#### this is end line flag line ,do not modify it!
2. syslog の設定を有効にするため、サービスの再起動を行います。
# service syslog restart
3. ログファイルの削除
# rm -rf /var/log/rflogview
4. パッケージの削除
下記のコマンドでパッケージを削除します。パッケージのバージョン番号は適宜お読みかえ下さい。
1) Asianux Server 3 ==MIRACLE LINUX V5 の場合
# rpm -e lime-logview-1.1.10-2AXS3
2) MIRACLE LINUX V4.0 の場合
# rpm -e rflogview-1.0-29AXS2
[注意事項]
本ドキュメントの内容は、予告なしに変更される場合があります。
本ドキュメントは、限られた評価環境における検証結果をもとに作成しており、 全ての環境での動作を保証するものではありません。
本ドキュメントの内容に基づき、導入、設定、運用を行なったことにより損害が生じた場合でも、
弊社はその損害についての責任を負いません。あくまでお客様のご判断にてご使用ください。
[更新履歴]
2010年 5月24日 新規作成
「warning: many lost ticks.」について
![]() MIRACLE LINUX V4.0 - Asianux Inside
MIRACLE LINUX V4.0 - Asianux Inside
![]() MIRACLE LINUX V4.0 - Asianux Inside for x86-64
MIRACLE LINUX V4.0 - Asianux Inside for x86-64
syslogに以下のようなメッセージが出力されることがあります。
1. ネットワークが高負荷の場合
Warning : meny lost ticks.
If your CPU support 'CPU Frequency scaling',You could ignore this warning
else your time source seems to be instable or some driver is hogging interupts
rip e1000_update_stats+0x781/0x788[e1000]
2.システムが高負荷の場合
Warning: many lost ticks.
If your CPU support 'CPU Frequency scaling',You could ignore this warning
else your time source seems to be instable or some driver is hogging interupts
rip __do_softirq+0x4d/0xd0
1のメッセージは Miracle Linux V4.0 SP2( kernel-2.6.9-42.7AXsmp)で出力されることを確認しております。これはe1000ドライバの不具合によるものです。アップデートパッケージにて修正されています。kernel-2.6.9-42.10AX以上のバージョンにアップデートをお願いいたします。
2のメッセージはMiracle Linux V4.0 SP4で出力されることを確認しております。これはシステムが高負荷状態で、かつDVD-ROM装置などIDEデバイスにアクセスしている場合に出力されることがあります。その場合、2のメッセージに加えて、以下のようなメッセージが出力されることがあります。
hda: command error: status=0x51 { DriveReady SeekComplete Error }
hda: command error: error=0x54
ide: failed opcode was 100
ATAPI device hda:
Error: Illegal request -- (Sense key=0x05)
Illegal mode for this track or incompatible medium -- (asc=0x64, ascq=0x00)
The failed "Read 10" packet command was:
"28 00 00 04 b6 40 00 00 02 00 00 00 00 00 00 00 "
end_request: I/O error, dev hda, sector 1235200
Buffer I/O error on device hda, logical block 308800
Buffer I/O error on device hda, logical block 308801
このような場合はIDEデバイスへのアクセスを控えるか、またはカーネルのブートパラメータに”hda=none”を設定し、IDEデバイスを無効にすることで、メッセージ出力が解消される可能性があります。
grub edit> kernel /boot/vmlinuz-2.6.18-128.7AXS3 ro root=LABEL=/ hda=none
ただし”hda=none”を設定した場合は対象のIDEデバイスが使用できなくなります。
「warning: many lost ticks.」のメッセージが出力されることでOSの時刻がずれることはございません。
[更新履歴]
2010年 4月 6日 新規作成
/usr を別パーティションにしている場合のアップグレードの諸注意
![]() Asianux Server 3 for x86(32bit)
Asianux Server 3 for x86(32bit)
![]() Asianux Server 3 for x86-64(64bit)
Asianux Server 3 for x86-64(64bit)
/usr を別パーティションで構成している環境の場合、device-mapper-1.02.32-1.AXS3にアップデートをした後、再起動を行うとvmsetup、fsckにて「libreadline.so.5」が見つからないと表示されOSが起動できなくなる問題があります。
この問題はdevice-mapper-1.02.39-1.1.AXS3以降のバージョンで修正されていますので、 パッケージを最新バージョンにアップデートいただくことで解決します。また、下記の[対処]方法によっても解決することが可能です。
https://tsn.miraclelinux.com/tsn_local/index.php?m=errata&a=detail&eid=1030
/usr を別パーティションで構成している環境の場合は、device-mapper-1.02.32-1.AXS3へのアップデートは行わないでください。
# cp /usr/lib64/libncurses.so.5.5 /lib64/
# cp /usr/lib64/libreadline.so.5.1 /lib64/
# cp /usr/lib64/libdmraid.so.1.0.0.rc13-17 /lib64/
# ldconfig
2010年 3月 30日 新規作成
2010年 4月 19日 修正
"detected DSPD enabled in EEPROM"について
![]() Asianux Server 3 for x86(32bit)
Asianux Server 3 for x86(32bit)
![]() Asianux Server 3 for x86-64(64bit)
Asianux Server 3 for x86-64(64bit)
![]() MIRACLE LINUX V4.0 - Asianux Inside
MIRACLE LINUX V4.0 - Asianux Inside
![]() MIRACLE LINUX V4.0 - Asianux Inside for x86-64
MIRACLE LINUX V4.0 - Asianux Inside for x86-64
intel社製のギガビット・イーサネットワークカード 82573(V/L/E)を使用しているハードウェア構成の場合、syslogに以下のようなメッセージが記録されることがあります。
kernel: e1000e 0000:0a:00.0: Warning: detected DSPD enabled in EEPROM
このメッセージは、intel社製のギガビット・イーサネットワークカード 82573(V/L/E)の省電力機能である、DSPD(Deep Smart Power Down)が有効(ON)になっていることを示すメッセージです。
DSPDが有効(ON)の場合は、通信障害が発生する可能性があるため、DSPDは無効(OFF)にすることを推奨いたします。詳細はintel社のURL先にある、"82573(V/L/E) TX Unit Hang Messages"の
ドキュメントを参照ください( http://downloadmirror.intel.com/9180/eng/README.txt )。
■ 82573(V/L/E)がeth0の場合の使用方法
# bash fixeep-82573-dspd.sh eth0
eth0: is a "82573E Gigabit Ethernet Controller"
This fixup is applicable to your hardware
executing command: ethtool -E eth0 magic 0x109a8086 offset 0x1e value 0xdf
Change made. You *MUST* reboot your machine before changes take effect!
EEPROMを書き換えた場合は、再起動を行ってください。
2010年 3月 1日 新規作成
HP社SmartArrayに接続したTAPEドライブが使用できない
[対象となる製品のバージョン]
![]() Asianux Server 3 ==MIRACLE LINUX V5
Asianux Server 3 ==MIRACLE LINUX V5
![]() MIRACLE LINUX V4.0 - Asianux Inside
MIRACLE LINUX V4.0 - Asianux Inside
![]() MIRACLE LINUX V3.0 - Asianux Inside
MIRACLE LINUX V3.0 - Asianux Inside
![]() MIRACLE LINUX Standard Edition V2.1
MIRACLE LINUX Standard Edition V2.1
[問題]
HP社SmartArrayに接続したTAPEドライブが使用できない。
[注意事項]
本ドキュメントは、各ソフトウェア開発元の情報およびマニュアル等を元にした参考情報です。本ドキュメントの内容は、予告なしに変更される場合があります。本ドキュメントは、限られた評価環境における検証結果をもとに作成しており、全ての環境での動作を保証するものではありません。本ドキュメントの内容に基づき、導入、設定、運用を行なったことにより損害が生じた場合でも、弊社はその損害についての責任を負いません。あくまでお客様のご判断にてご使用ください。本ドキュメントで使用しているソフトウェアのセキュリティ等の詳細な設定につきましては、マニュアル等をご参照ください。
[問題詳細]
HP社のSmartArrayにTAPEドライブを接続した場合、通常のインストール作業だけではTAPEドライブは認識させず使用できません。
[回答]
1.TAPEドライブを使用する前に、以下のコマンドを実行します。
※起動時に自動的に認識させるには/etc/rc.localに下記のコマンドを追記してください。
# echo "engage scsi" > /proc/driver/cciss/cciss0
※すべてのファイル(/proc/driver/cciss/cciss[数字])に対して同様にコマンドを実行します。
# echo "engage scsi" > /proc/driver/cciss/cciss0
# echo "engage scsi" > /proc/driver/cciss/cciss1
...
2.TAPEドライブが認識されたことを確認します。
# cat /proc/scsi/scsi
Host: scsi2 Channel: 00 Id: 00 Lun: 00
Vendor: HP Model: Ultrium 3-SCSI Rev: Q25W
Type: Sequential-Access ANSI SCSI revision: 05
Host: scsi2 Channel: 00 Id: 01 Lun: 00
Vendor: HP Model: 1x8 G2 AUTOLDR Rev: 2.80
Type: Medium Changer ANSI SCSI revision: 05
3.TAPEドライブのデバイスファイルが正常に作成されていることを確認します。
# ls -l /dev/st* /dev/nst*
crw-rw---- 1 root disk 9, 128 12月 25 04:24 /dev/nst0
crw-rw---- 1 root disk 9, 0 12月 25 04:24 /dev/st0
[参考情報]
・このドキュメントはHP社のページを参考に作成しました。あわせて以下のURLをご確認ください。
SmartArray/ccissでの TAPE(SCSI)サポートについて
SmartArray/ccissでの TAPE(SAS)サポートについて
・詳細情報は下記のドキュメントにも記載されています。
/usr/share/doc/kernel-doc-バージョン番号/Documentation/cciss.txt
[更新履歴]
2010年 2月 25日 新規作成
php実行時のWarningメッセージ出力について
[対象となる製品のバージョン]
![]() Asianux Server 3 for x86(32bit)
Asianux Server 3 for x86(32bit)
![]() Asianux Server 3 for x86-64(64bit)
Asianux Server 3 for x86-64(64bit)
![]() MIRACLE LINUX V4.0 - Asianux Inside
MIRACLE LINUX V4.0 - Asianux Inside
![]() MIRACLE LINUX V4.0 - Asianux Inside for x86-64
MIRACLE LINUX V4.0 - Asianux Inside for x86-64
![]() MIRACLE LINUX V3.0 - Asianux Inside
MIRACLE LINUX V3.0 - Asianux Inside
![]() MIRACLE LINUX V3.0 - Asianux Inside for x86-64
MIRACLE LINUX V3.0 - Asianux Inside for x86-64
[注意事項]
本ドキュメントは、各ソフトウェア開発元の情報およびマニュアル等を元にした参考情報です。本ドキュメントの内容は、予告なしに変更される場合があります。本ドキュメントは、限られた評価環境における検証結果をもとに作成しており、全ての環境での動作を保証するものではありません。本ドキュメントの内容に基づき、導入、設定、運用を行なったことにより損害が生じた場合でも、弊社はその損害についての責任を負いません。あくまでお客様のご判断にてご使用ください。
[現象]
一般ユーザー、または、rootユーザー権限で、コマンドラインからphpを実行すると以下の様なWarningメッセージが出力される場合があります。
# php -v
PHP Warning: PHP Startup: Unable to load dynamic library'/usr/lib/php/modules/oci8.so'
/usr/lib/php/modules/oci8.so: undefinedsymbol: xxxxxxx in Unknown on line 0
(xxxxxxxにはoci8.soライブラリ内のシンボル名が表示されます。)
[詳細]
このWarningメッセージは、php-oci8が使用するOracle Databaseのライブラリが正しく読み込まれなかったことを意味し、Oracle Databaseのライブラリへのパスが正しく設定がされていない場合に出力されます。 php-oci8はphpでOracle Databaseを操作する為のパッケージです。Oracle Databaseと連携していない場合、このWarningメッセージが出力されたとしても、phpの動作に影響はありません。Oracle Databaseを使用している場合、phpからOracle Databaseの操作が出来無い可能性があります。
[対処方法]
本問題の対処方法はOracle Databaseのインストールの有無によって異なります。
ご使用の環境に当てはまる方法を行って下さい。
-
Oracle Databaseを使用していない場合
Oracle Databaseと連携をしない場合、このWarningメッセージは無視することができます。また、php-oci8のパッケージを削除することでWarningメッセージを止める事ができます。このパッケージを削除することによるphpの動作への影響はありません。
# rpm -qa |grep php-oci8
php-oci8-5.1.6-23.2AXS3
# rpm -e php-oci8-5.1.6-23.2AXS3
-
Oracle Databaseを使用している場合
実行するユーザーの環境変数ORACLE_HOME,LD_LIBRARY_PATHにパスを正しく設定して頂く事でライブラリが正しく読み込まれるようになり、Warningメッセージの出力を止める事が出来ます。
インストールされているOracle Databaseのライブラリを設定します。
# export ORACLE_HOME=/opt/app/oracle/product/xx.x.xx/db_1
(ORACLE_HOMEにはOracle Databaseのインストール先ディレクトリを指定してください。)
# export LD_LIBRARY_PATH=$ORACLE_HOME/lib
常時使用する場合にはユーザーの設定ファイルに以下の設定を追記します。
例)ユーザー”user1”に対して設定を行う場合
/home/user1/.bashrc
export ORACLE_HOME=/opt/app/oracle/product/xx.x.xx/db_1
(ORACLE_HOMEにはOracle Databaseのインストール先ディレクトリを指定してください。)
export LD_LIBRARY_PATH=$ORACLE_HOME/lib
[更新履歴]
2010年 2月25日 新規作成
新 2010 インテル® Core™ プロセッサー・ファミリーでのAsianux Server 3のインストール方法
[対象となる製品のバージョン]
![]() Asianux Server 3 for x86(32bit)
Asianux Server 3 for x86(32bit)
![]() Asianux Server 3 for x86-64(64bit)
Asianux Server 3 for x86-64(64bit)
[問題詳細]
Core i5 600シリーズ、Core i3-500シリーズなどGPUが内蔵された新 2010 インテル® Core™ プロセッサー・ファミリー(開発コード名Clarkdale)を搭載した機種において、グラフィックが動作しない場合があります。その場合は通常のAsianux Server 3インストールに加え、アップデートをする必要があります。
[対処方法]
Asianux Server 3 ==MIRACLE LINUX V5 SP2のインストールを例に記述します。
1. Asianux Server 3 ==MIRACLE LINUX V5 SP2 をテキストモードでインストールします。
下記URLにあるAsianux Server 3 ==MIRACLE LINUX V5 SP2 の製品版インストレーションガイド「 第5章 テキストモード」をご覧ください。
https://users.miraclelinux.com/products/linux/axs3/pdf/axs3_install_guide_sp2.pdf
2. Asianux Server 3 ==MIRACLE LINUX V5 SP2 を起動します。
-
製品版インストレーションガイド「5.12 ランレベルとX設定のカスタマイズ」においてDefault Loginの項目で、ログインの種類に[Graphical]を選択した場合は、grubのカーネル選択画面で以下のようにブートパラメータに 3と記述し、テキストモードで起動してください。
grub edit> kernel /boot/vmlinuz-2.6.18-128.7AXS3 ro root=LABEL=/ 3
-
[Text]を選択してインストールした場合はそのままOSを起動してください。
3. /etc/X11/xorg.conf の設定を変更してください。
xorg.confのModesの行をコメントアウトしてください。
# vi /etc/X11/xorg.conf
・・・・・Section "Screen"
Identifier "Screen0"
Device "Videocard0"
DefaultDepth 24
SubSection "Display"
Viewport 0 0
Depth 24
# Modes "800x600" "640x480" <― この行をコメントアウトしてください
EndSubSection
EndSection
4. xorgのアップデートパッケージをダウンロードします。
下記URLよりxorgに関するパッケージをダウンロードします。ご利用のOSに合わせてRPMパッケージをダウンロードしてください。
5. ダウンロードしたRPMパッケージをインストールします。
# rpm -Uhv xorg-x11-server-*67*
準備中... ########################################### [100%]1:xorg-x11-server-Xorg ########################################### [ 20%]
2:xorg-x11-server-Xdmx ########################################### [ 40%]
3:xorg-x11-server-Xnest ########################################### [ 60%]
4:xorg-x11-server-Xvfb ########################################### [ 80%]
5:xorg-x11-server-sdk ########################################### [100%]
アップデート後、グラフィック画面の表示が可能となります。
[注意事項]
本ドキュメントは、各ソフトウェア開発元の情報およびマニュアル等を元にした参考情報です。
本ドキュメントの内容は、予告なしに変更される場合があります。
本ドキュメントは、限られた評価環境における検証結果をもとに作成しており、全ての環境での動作を保証するものではありません。
本ドキュメントの内容に基づき、導入、設定、運用を行ったことにより損害が生じた場合でも、弊社はその損害についての責任を負いません。あくまでお客様のご判断にてご使用ください。
[更新履歴]
2010年 2月 16日 新規作成
IPMI watchdogの設定方法
![]() Asianux Server4 SP1 for x86(32bit)
Asianux Server4 SP1 for x86(32bit)
![]() Asianux Server4 SP1 for x86-64(64bit)
Asianux Server4 SP1 for x86-64(64bit)
![]() Asianux Server 3 for x86(32bit)
Asianux Server 3 for x86(32bit)
![]() Asianux Server 3 for x86-64(64bit)
Asianux Server 3 for x86-64(64bit)
[概要]
本ドキュメントではカーネルのIPMI watchdogの設定方法について説明します。
IPMI watchdogとはIPMI(Intelligent Platform Management Interface) のwatchdog timer機能により、なんらかの原因でシステムがフリーズした状態を検出する機能です。これによりシステムのデッドロック、または無限ループなどの不具合を検出することが可能です。
また検出後にダンプ採取、自動でハードウェアリセットなど任意の動作をさせることができます。
[前提条件]
・IPMIコントローラがサーバに搭載されている必要があります。
確認するにはサーバのスペックを確認していだくか、下記の方法で確認が可能です。
IPMIコントローラが備わっている場合は以下のコマンドが成功しモジュールをロードすることができます。
# modprobe ipmi_si
[設定手順]
1.IPMI watchdogの設定
/etc/sysconfig/ipmiを任意のエディタで開き以下の行を編集します。以下は設定例です。
・・・
IPMI_WATCHDOG=yes
・・・
IPMI_WATCHDOG_OPTIONS="timeout=60 action=reset pretimeout=30 preaction=pre_int preop=preop_panic"
・・・
各パラメータの意味は以下になります。
| timeout | システムがフリーズ状態と判断する時間を指定します。watchdogが最後にリセットされてからaction=で指定した動作をさせるタイムアウト時間になります。単位は秒となります。 |
| action |
reset, none, power_cycle, power_offのいずれかを指定します。 ・resetはH/Wリセットでリブートします。 ・noneはなにもしません。 ・power_cycleはいったん電源をオフにしたあと、オンにます。 ・power_offは電源をオフにします。 |
| pretimeout | preaction=で指定した動作をさせるタイムアウト時間を指定します。単位は秒となります。 |
| preaction |
pre_none,pre_smi, pre_nmi, pre_intのいずれかを指定します。preopを動作させる通知手段を設定します。 ・pre_noneはなにもしません。 ・pre_smiはIPMI物理インターフェースであるSMI(System Management ・pre_nmiはNMI割り込みにより通知します。 ・pre_intは割り込みにより通知します。 |
| preop |
preop_none, preop_panic のいずれかを指定します。 ・preop_noneはなにもしません。 ・preop_panicはカーネルパニックを発生させます。 |
2.IPMI watchdogドライバのロード
(1) 以下のコマンドにて IPMI watchdogドライバをロードします。
# service ipmi start
Starting ipmi drivers: [ OK ]
Starting ipmi_watchdog driver: [ OK ]
(2) システムの起動時に自動でIPMI watchdogを有効にするには、以下のコマンドを実行します。
# chkconfig ipmi on
ドライバのロード後には以下のメッセージが出力されます。
# dmesg
・・・・
ipmi: Found new BMC (man_id: 0x0002a2, prod_id: 0x0000, dev_id: 0x20)
IPMI kcs interface initialized
ipmi device interface
IPMI Watchdog: driver initialized
以上でデバイスファイル/dev/watchdogが作成されます。
3.watchdogデーモンの起動
(1) /etc/watchdog.confを開いて以下の行をコメントアウトします。
#watchdog-device = /dev/watchdog
(2) watchdogデーモンを起動します。
# service watchdog start
(3) システムの起動時に自動でwatchdogデーモンを起動するには、以下のコマンドを実行します。
# chkconfig watchdog on
[注意事項]
本ドキュメントの内容は、予告なしに変更される場合があります。
本ドキュメントは、限られた評価環境における検証結果をもとに作成しており、全ての環境での動作を保証するものではありません。
本ドキュメントの内容に基づき、導入、設定、運用を行ったことにより損害が生じた場合でも、弊社はその損害についての責任を負いません。あくまでお客様のご判断にてご使用ください。
[更新履歴]
2012年 1月27日 watchdogの起動方法を追加
2010年 2月 9日 新規作成