|
 Samba 国際化プロジェクト > iconvについて
Samba 国際化プロジェクト > iconvについて
iconvについて
Sambaでは 3.0から、文字コード変換にiconvを使用するようになりました。 目次1. 概要オープンソースソフトウェアおよびフリーソフトウェアにおいてもソフトウェアの 国際化対応を行うために文字列処理の際に UCS(Unicode) を使う事が多くなってき ています。 UCS を用いる主な理由としては、各国のエンコーディングを考慮したコードを書か なくてもプログラム内部では UCS で処理して入出力の際にエンコーディング変換 を行えば良いという考えがあるようです。 UCS と各エンコーディングの変換を行う関数として iconv() がありますが、オー プンソースソフトウェアやフリーソフトウェアで利用されている libiconv や glibc2 での iconv() の実装では日本語での利用が実用にならないという問題があ ります。 この問題に対して各ソフトウェアの日本のコミュニティーが個別に対応していると いうのが現状で、必ずしも包括的な解決策がとられているわけではありません。 この文書は、glibc/libiconv の iconv() によるエンコーディング変換で日本語を 扱う際にどのような問題があるかを取り上げ iconv() を用いた日本語処理の問題 を共有する事を目的とします。 また、問題となるマルチバイト文字の一覧を用意しました。以下のリンクからダウンロードすることができます。
ダウンロード:
2. libiconv/glibc の問題点2-1. cp932 の問題点libiconv/glibc には、Windows コードページ 932 と UCS(Unicode) のエンコーディング変換を行うコンバーターとして cp932 が用意されていますが、次の点がマイクロソフトの変換と異なります。
1.、2. の違いにより、Windows で Unicode に変換したデータがオリジナルのlibiconv で正しく変換できず、また、libiconv で Unicode に変換したデータがWindows で正しく変換できないという問題が生じます。
3. の違いにより、シフトJIS(cp932)で重複符号化されている文字の同一視していないソフトでの文字列比較で問題が生じる可能性があります。 2-2. JIS系エンコーディングの問題libiconv/glibc の Shift_JIS/EUC-JP/ISO-2022-JP の各エンコーディングの変換は次の問題により限定なものになってしまっています。
2-3. cp932とeuc-jp,iso-2022-jplibiconv/glibc では、表1の libiconv/glibc の欄の UCS のコードポイントを採用する事で cp932 と euc-jp や iso-2022-jp との相互変換を実現する事が出来ていますがマイクロソフトの UCS との互換性がありません。 cp932 の変換をマイクロソフトの変換にあわせると、今度は、euc-jp や iso-2022-jpとの相互変換が出来なくなります。
UCS 経由でのエンコーディング変換の際には、各コンバーター間で中継する UCS のコードポイントが一致している必要があります。
表6 JISのUCSマッピングとMSのUCSマッピングの相違点
表7 の (1), (2) の部分は Windows では、それぞれ次のようなコードページで対応しています。
オープングループ/日本ベンダ協議会では、次のような codeset 名を定義しています。
標準情報(TR) TR X 0015:1999 XML日本語プロファイル では次のような charset 名が定義されています。
3. libiconv/glibc パッチの内容3-1. libiconv パッチでの修正内容
3-2. glibc パッチでの修正内容
4. 課題
5. 参考
変換表がベンダーによって異なる (2002-04-04)
http://www.debian.or.jp/~kubota/unicode-symbols-map2.html.ja Java Character Encodings > 既存の文字コードを処理する際の問題点 http://www.ingrid.org/java/i18n/encoding/ Troll Tech と交渉して Qt/KDE の国際化/日本語化をした方のページ http://www.asahi-net.or.jp/~hc3j-tkg/ 従来の文字コードとUnicodeの対応に関する諸問題 http://euc.jp/i18n/ucsnote.ja.html (eucjp-ms) Unicode とユーザ定義文字・ベンダ定義文字に関する問題点と解決策 JIS-Unicode変換において問題の起こりにくい変換表 http://hp.vector.co.jp/authors/VA010341/unicode/
Windows-31J 情報
http://www2d.biglobe.ne.jp/~msyk/charcode/cp932/index.html libiconv-1.8-cp932-patch.diff.gz http://www2d.biglobe.ne.jp/~msyk/software/libiconv-patch.html glibc cp932/eucjp-ms パッチ http://www2d.biglobe.ne.jp/~msyk/software/glibc/ |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
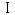
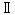
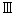
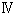
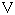
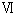
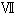

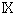
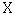

|